很多时候,我们的程序出现的“性能问题”,其实是我们自己写的那”坨”代码的问题,是自己Coding的问题,是Mysql的DML语句使用的问题。
以下是我总结的关于MySQL DML语句的使用中需要注意的点。
对于select *要时刻保持谨慎的态度
绝大多数情况,是不需要select * 的。一旦使用了这种语句,便会让优化器无法完成索引覆盖扫描这类优化,而且还会增加额外的I/O、内存和CPU的消耗。
当然,使用select *也并不是全是坏处,合理的使用select * 可以简化开发,提高相同代码的复用性。
是否扫描的太多额外的记录
有时候会发现某些查询可能需要读取几千行数据,但是仅返回几条或者很少的结果,可以使用以下方式去优化:
- 看看能否改表结构。例如使用汇总表
- 看看获取数据结果的方式是否最优,获取路劲是否已经是最短。
- 使用覆盖索引,把所有需要的列都放到索引中,以减少返回表中对应行中取数据的步骤。
切分某些SQL语句
传统的互联网系统中,强调网络连接尽量少,数据层尽可能在一次连接中完成尽可能多的工作,防止建立多次链接,但是这种想法对于MySQL并不适用,MySQL从设计上让连接和断开都很轻量,在一般服务器上可以支持每秒超过10万的查询。
所以对于有些场景下,可以将一个大的查询“分而治之”,切分成小查询,然后再组合起来。例如以下情况:
- 对于全量数据查询变成分页。假如一张表中有数千万条数据,一次select all,肯定是不行的。可以换成一次取一部分,把一次的压力分摊。
- 删除大量旧数据的时候,不要一个大的语句一次性清完,推荐
一次删一万条。如果用一个大的语句一次性完成的话,可能需要一次锁住大量数据,占满大量日志事务,让Mysql停在那儿了,为避免这种情况发生,最好一次性删除一万条左右的数据,然后每次删完暂停一会儿再操作,将服务器上的一次性压力分散。
注意:虽然Mysql建立连接十分轻量,但是这不意味着可以逐条循环中查询然后再拼接,这样效率依然是非常慢,而且通常是工作中sql优化的点。
慎用join操作
这算是一条禁忌吧,很多公司的互联网产品都杜绝join操作,换成先从一张表中先取出数据id,再从另外一张表中使用where in查询的两次单表查询操作。主要是以下几点原因:
- 让应用的缓存(redis、memcache等)更高效。例如在第一张表中查询出部分id了,如果命中了缓存,就可以省去一条where in语句了。
- 更容易应对业务的发展,方便对数据库进行拆分,更容易做到高性能和高扩展。
- 对where in中的id进行升序排序后,查询效率比join的随机关联更高效
- 减少多余的查询。在应用层中两次查询,意味着对某条记录应用只需要查询一次,而使用join可能需要重复的扫描访问一部分数据。
- 单张表查询可以减少锁的竞争。
假如非用不可,可以采用以下方式来优化:
- 确保
ON或者using子句中的列上有索引 - 确保任何的
group by和order by中的表达式只涉及到一个表中的列。
在性能要求比较高的场景中,杜绝查询中使用临时表
MySQL的临时表示没有任何索引的,使用临时表一般都意味着性能比较低,因此在对性能要求比较高的场景中,最好不要使用带有临时表的操作:
- 未带索引的字段上的
group by操作。 UNION查询。- 查询语句中的子查询。
- 部分
order by操作,例如distinct函数和order by一起使用且distinct和order by同一个字段。再例如某些情况下group by和order by字段不同。
具体是否用到临时表,可以通过explain来查看,查看Extra列的结果,如果出现Using temporary则需要注意。
count()函数优化
count()函数有一点需要特别注意:它是不统计值为NULL的字段的!所以:不能指定查询结果的某一列,来统计结果行数。即count(xx column) 不太好。
如果想要统计结果集,就使用count(*),性能也会很好。
尽量不使用子查询
尽量别使用子查询,尽可能的使用关联来代替
优化分页limit
通常我们在分页的时候,通常使用的是limit 50, 10这种语句。数据少还不错,但是当数据偏移量非常大的时候,性能就会出现问题,例如select xx,xxx from test_table limit 100000020, 20。扫描了100000020条数据,才返回20条数据。这个时候我们可以用一下两种方式来优化:
利用between and 和主键索引
利用主键自增id,我们如果知道了分页的上边界,以上查询可以改写为:select xxx, xxx from test_table where id between xxxxx and xxxx。
利用自增主键索引、order by加limit,不使用offset
limit和offset的问题,其实就是offset的问题,它会导致MySQL扫描大量不需要的行然后再抛弃掉。如果使用某个标签记录上一次所取数据的位置,那么下次就可以直接从书签位置开始扫描,这样就可以避免使用offset。
例如以上查询可以改为:
第一组数据:``select xxx, xxxx from test_table order by id desc limit 20;
这样就拿到了本次数据和下次数据的分解id值,则下一页查询就知道可以:select xxx, xxx from test_table where id < '上页id分界值' order by id desc limit 20
熟悉并灵活使用explain
以下是mysql执行查询的整个过程,explain可以查看图中标红部分,
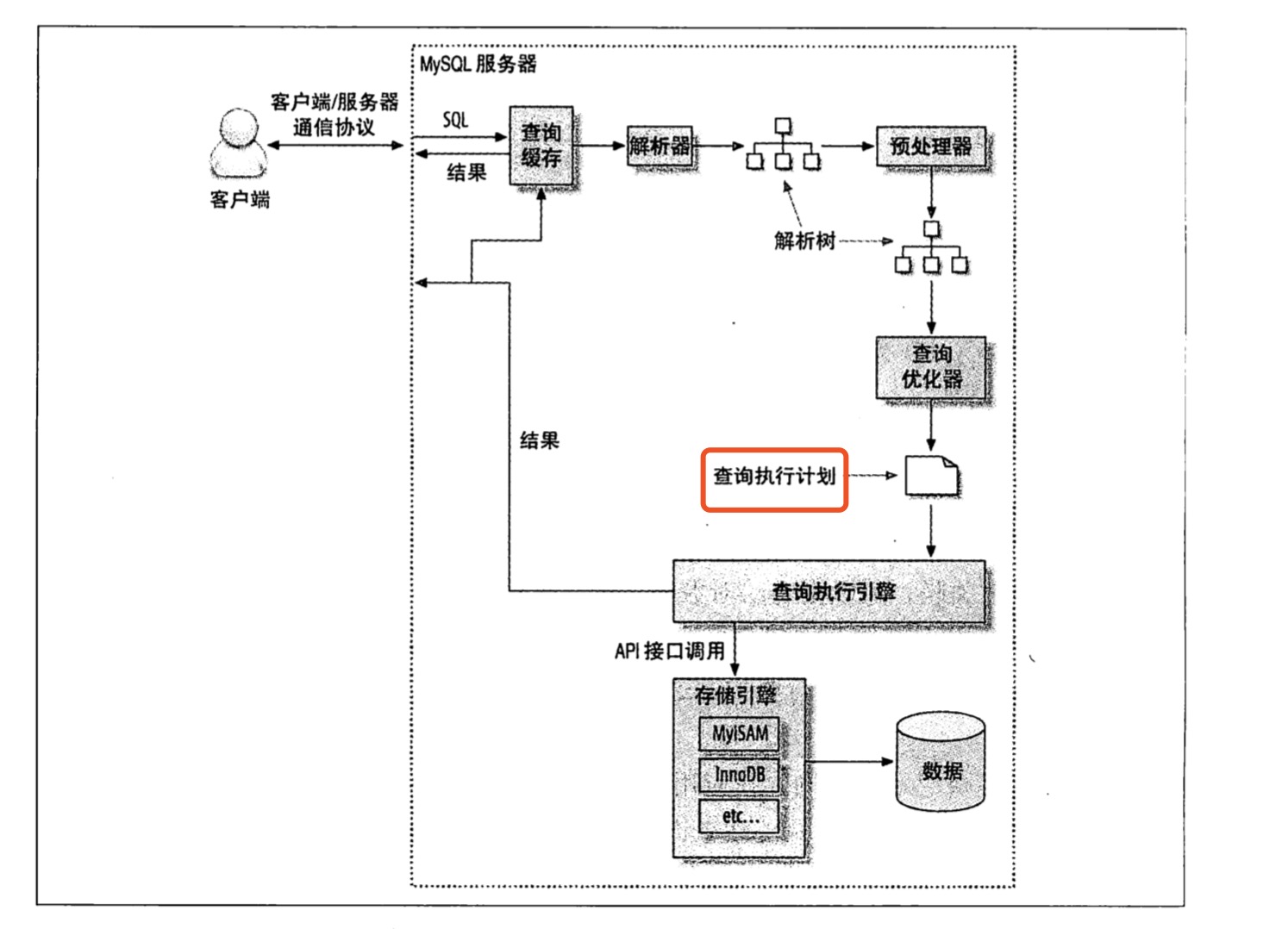
explain会展示很多字段和内容,其中的内容往往不好记,使用的时候,可以查看以下图解内容:
explain图解