今天我们来聊聊MySQL中InnoDB存储引擎的锁。
锁是数据库系统系统区别于文件系统的一个关键特性。
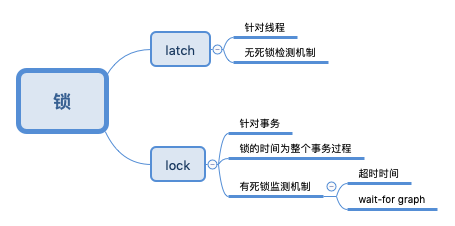
lock和 latch
latch
latch在MySQL中是用来保证并发多线程操作操作临界资源的锁,锁定的对象线程,是和咱们使用的Java等传统语言中的锁意义相近,而且没有死锁检测的机制。
lock
lock是MySQL中在事务中使用的锁,锁定的对象是事务,来锁定数据库中表、页、行;通常只有在事务commit或者rollback后进行释放。lock是有死锁机制的,当出现死锁时,lock有死锁机制来解决死锁问题:超时时间(参数innodb_lock_wait_timeout)、wait-for graph。
我们通常讲的MySQL的“锁”,一般就是说的lock。
以下就是InnoDB中“锁”的大分类:
lock的种类
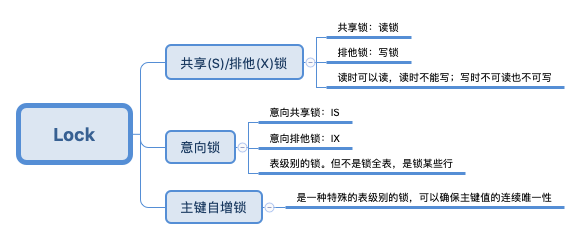
MySQL Lock大体上可以分为:表锁、行锁、意向锁三种。
共享/排他锁
行锁分为:S Lock和X Lock。S Lock :读锁;X Lock:写锁。
两锁之间的兼容性如下。
1 | X S |
简单总结为:读锁可以读,读锁不可写;写锁不可读也tm不可写。
意向锁
InnoDB支持多粒度的锁,即:允许表锁和行锁同时存在。
但是,假如表锁覆盖了行锁的数据,所以表锁和行锁也会产生冲突。如:
1 | trx1 BEGI |
这样,表锁和行锁之间就产生了冲突,为了解决这种表锁和行锁共存的问题,就产生了意向锁这个东西。
意向锁:从字面意思也很好理解,就是提前表明一个“意向”。
意向锁分为:
意向共享锁。它预示着,事务正在或者有意向对表中的”某些行”加S锁。select xxxx lock in share mode,要设置IS锁。意向排他锁。它预示着,事务正在或者有意向表中的“某些行”加X锁。select xxx for update,要设置IX锁。
但意向锁仅仅是表明意向,它其实非常弱,意向锁之间可以相互并行,并不是排斥的:
意向锁之间的兼容性问题:
1 | IS IX |
但是,意向锁可以和表锁互斥。(注意:文中 S 和 X均为表锁)
1 | S X |
于是,上述现象就变为了:
1 | trx1 BEGIN |
也许有人会问:“意向锁存在的意义是什么呢?没有意向锁,行锁和表锁照样可以共存啊?”
试问如何共存?
“查看表中某一行存在X锁”
“如何查看呢?”
唯有全表扫描…
意向锁的存在就是解决了“全表扫描”的性能问题,所以,意向锁一定是“表级”锁,告诉整张表XXX行存在X锁。此时假如进行表操作就会被阻塞。
主键自增锁
自增锁(auto-inc Locks)是一种特殊的表级锁,专门针对事务插入AUTO_INCREMENT类型的列,往往就是主键列。可以保证主键的值自增是“原子操作”,不会出现一致性、唯一性问题。
行锁的具体分类
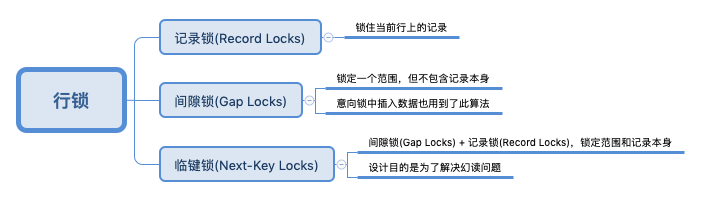
InnoDB存储引擎有以上3种行锁算法。以上3种,都是实现在索引上的。
记录锁(Record Lock)
记录锁(Record Lock)总是会去锁住索引记录。
假如没有任何一个索引,那么InnoDB会锁住隐形创建的那个主键。
注意:这里锁的是索引,不一定只是主键索引哦,还可能是二级普通索引。
间隙锁(Gap Lock)
顾名思义,它会封锁索引记录中的“缝隙”,让制其他事务在“缝隙”中插入数据。
它锁定的是一个不包含索引本身的范围。
例如以下索引数据: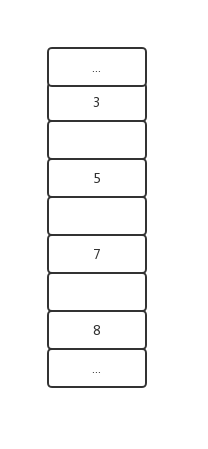
间隙锁(Gap Lock)可以锁的将是以下范围
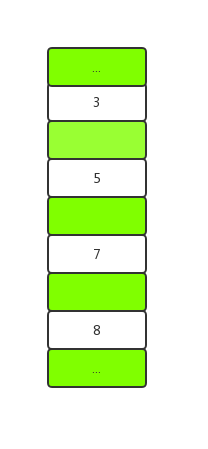
具体的范围还要根据查询条件不同而定。
间隙锁开启的事务隔离级别是 Repeatable Read,如果把数据库事务级别降为Read Committed(默认是 Repeatable Read),间隙锁则会自动失效。
临键锁(Next-Key Lock)
Next-Key Lock可以说是记录锁(Record Lock)和间隙锁(Gap Lock)的组合,既封锁了”缝隙”,又封锁了索引本身。
还是上面的索引数据:
临键锁(Next-Key Lock)锁住的范围将是:
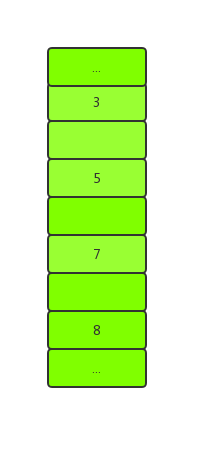
Next-key Lock在索引具有唯一性的时候,例如主键索引的数据,将会降级为记录锁(Read Lock),以增加并发性。
例如:
1 | T1 T2 |
以上情况,就会把Next-key Lock降级为记录锁(Read Lock)
再谈不可重复读(No Reaptable Read)和幻读(Phantom Problem)
有些很权威的书中认为这俩是同一个概念,例如:<<MySQL技术内幕 InnoDB存储引擎>>。
但是就目前网络上的众多总结和个人看法,认为区别如下:
不可重复读:修改。在同一个事务中,主要是说多次读取一条记录, 发现该记录中某些列值被修改过。幻读:增加或者删除。在同一个事务中,同一条完全相同的查询语句返回的结果集行数不同。
认真的说,多版本并发控制 MVCC(读)和 临键锁 Next-Key Lock(写)共同解决了幻读问题。
关于MVCC的原理,就是每份数据会有快照,事务中读取数据(简单的select xxx from,select xx from xx for update或者select xx from xxx in share mode不行)的时候,如果数据被锁住了,就读以前留下的快照数据。在此不过多赘述了。
以下为多版本并发控制原理图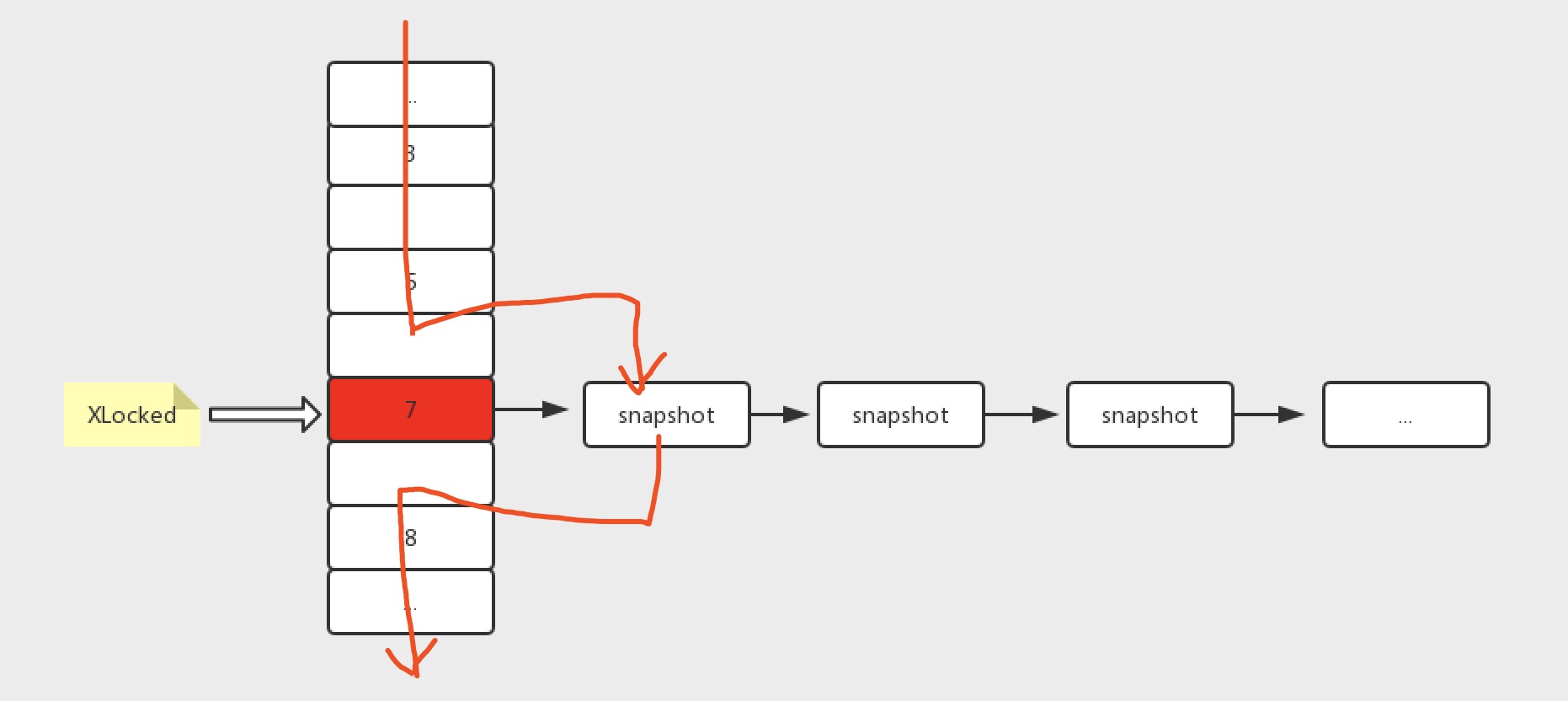
MVCC只在Read Committed和Repeatable Read下会开启。但是在这两种隔离级别下对于快照指定的数据定义不同。
在Read Committed下,MVCC读取的是被锁定数据的最新的一份数据。
在Repeatable Read下,MVCC读取的是事务刚开始时候的数据。