在分布式系统中,通常会用到分布式ID来标注数据的唯一性,而分布式ID的生成方式又多种多样,今天我们就来讨论一下主流的分布式ID生成策略。
分布式ID基本需求
- 全局唯一
- 趋势递增
- 信息安全
全局唯一
这是基本要求,不必解释
趋势递增
为什么要趋势递增呢?
第一,由于我们的分布式ID,是用来标识数据唯一性的,所以多数时候会被定义为主键或者唯一索引。
第二,并且绝大多数互联网公司使用的数据库是:MySQL,存储引擎为innoDB。
对于B + Tree这个数据结构来讲,数据以自增顺序来写入的话,b+tree的结构不会时常被打乱重塑,存取效率是最高的。
信息安全
由于数据是递增的,所以,恶意用户的可以根据当前ID推测出下一个,非常危险,所以,我们的分布式ID尽量做到不易被破解。
数据库主键自增(Flicker)
基于数据库主键自增的方案,名为Flicker。
主要是利用MySQL的自增主键来实现分布式ID。
以下为Flicker实现分布式ID的主流做法:
1、需要单独建立一个数据库实例:flicker
1 | create database `flicker`; |
2、创建一张表:sequence_id
1 | create table sequence_id( |
为什么用MyISAM?不用InnoDB?个人推测原因是:flicker算法出来的时候,MySQL的默认引擎还依旧是MyISAM而不是InnoDB,作者只是想用默认引擎而已,并无其他原因。
- stub: 票根,对应需要生成 Id 的业务方编码,可以是项目名、表名甚至是服务器 IP 地址。
- stub 要设置为唯一索引
3、使用以下SQL来获取ID
1 | REPLACE INTO ticket_center (stub) VALUES ('test'); |
Replace into 先尝试插入数据到表中,如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据, 否则直接插入新数据。
一般stub为特殊的相同的值。
这样,一个分布式ID系统算是可以搭建运行了。但是,有人要问:“这是一个单实例、单点的系统,万一挂了,岂不是影响所有关联的业务方?”
改进升华
是的。确实如此,因此又有人说:“可以利用MySQL主从模式,主库挂了,使用从库。”
这只能算是一种比较low的策略,因为如果主库挂了,从库没来得及同步,就会生成重复的ID。
有没有更好的方法呢?
我们可以使用“双主模式“,也就是有两个MySQL实例,这两个都能生成ID。
如图所示,我们原来的模式: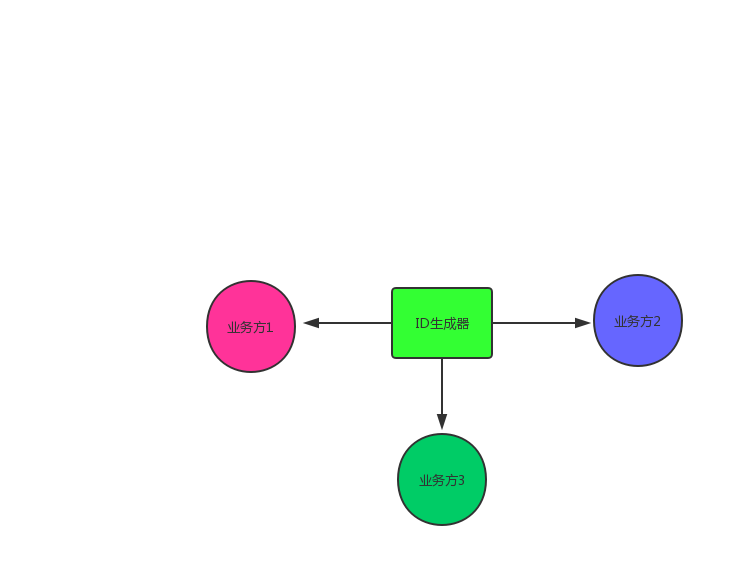
双主模式是该怎么样呢?如何保持唯一性?
我们可以让一台实例生成奇数ID,另一台生成偶数ID。
奇数那一台:
1 | set @@auto_increment_offset = 1; -- 起始值 |
偶数那一台:
1 | set @@auto_increment_offset = 2; -- 起始值 |
当两台都OK的时候,随机取其中的一台生成ID;若其中一台挂了,则取另外一台生成ID。
如图所示: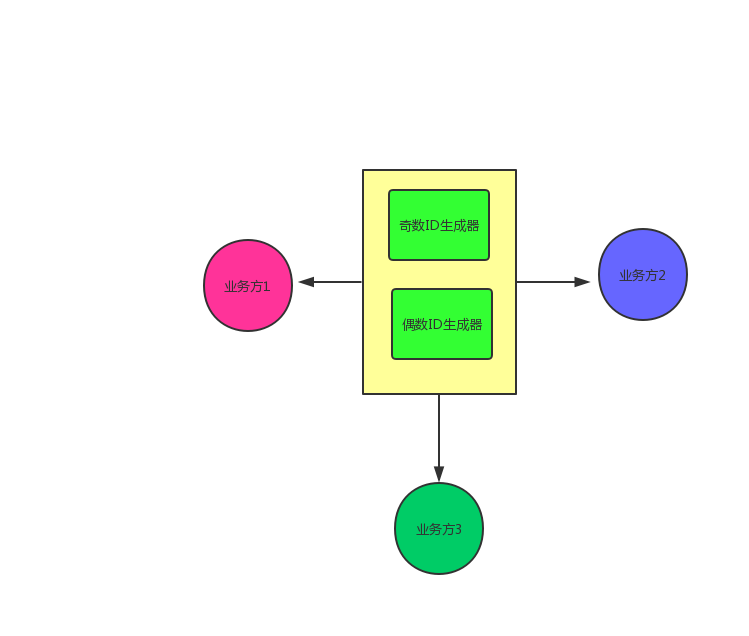
细心会发现,N个节点,只要起始值为1,2,…N,然后步长为N,就会生成各不相同的ID。(PS:后文有推导公式)
总结
优点:
- 简单。充分利用了数据库自增 ID 机制,生成的 ID 有序递增。
- ID递增
缺点:
- 并发量不大。
- 水平扩展困难,系统定义好了起始值、步长和机器台数,跑起来之后,添加额外的机器困难。
- 安全系数低
Redis
Redis为单线程的,所以操作为原子操作,利用incrby命令可以生成唯一的递增ID。
原理
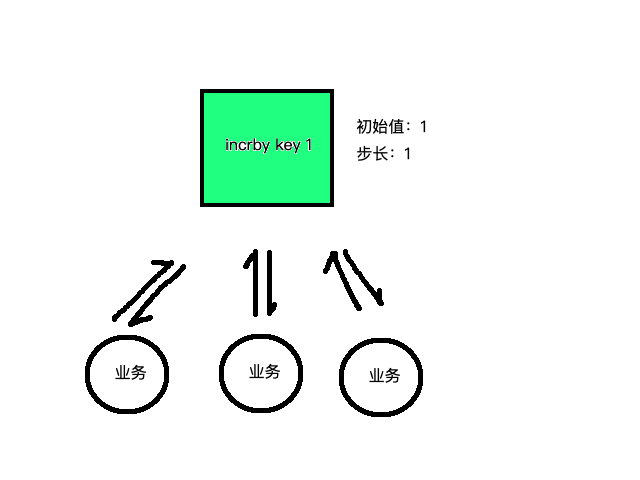
单机单点,吞吐不够,加集群
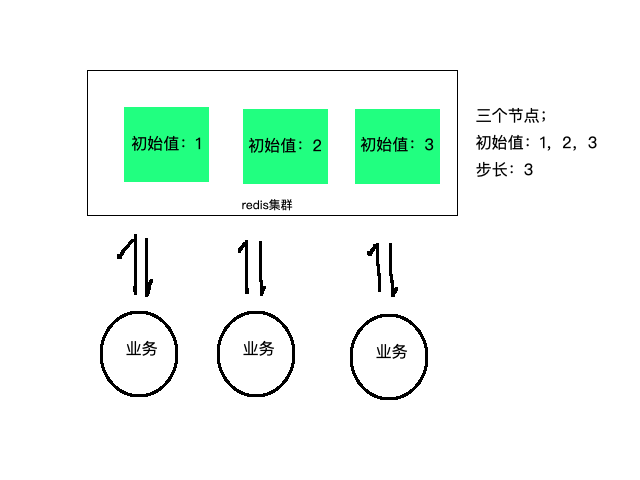
假设N个节点,则步长为N,节点起始值为1,2,…… N。则三个节点生成的ID一定不同!
想想为什么?
以上信息条件可以转化为数学推理:1 + x * N = 2 + y * N 且 x、y、N都为整成数且N不为1,试问等式存不存在?
1 | 答: |
同理可证1 + x * N = 3 + y * N 和2 + x * N = 3 + y * N 也是如此。
优点
- 性能显然高于基于数据库的
Flicker方案 - ID递增
缺点
- 水平扩展困难
- Redis集群宕机可能会产生重复的id
- 易破解
UUID
想必这个大家都熟悉。UUID是通用唯一识别码(Universally Unique Identifier)的缩写,是一种软件建构的标准,亦为开放软件基金会组织在分布式计算环境领域的一部分。
原理
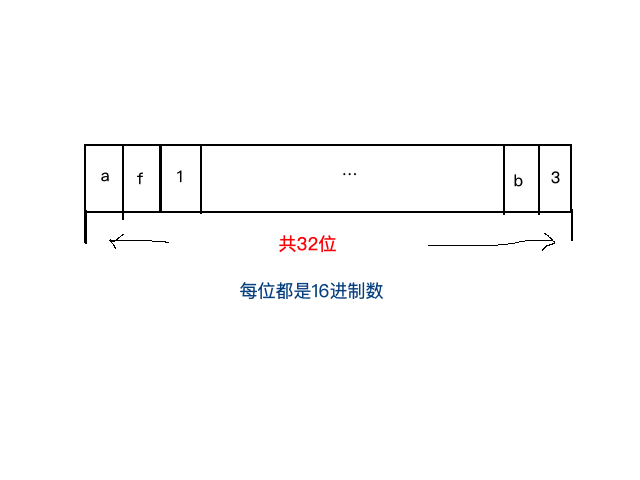
UUID是由一组32位数的16进制数字所构成,是故UUID理论上的总数为16^32 = 2^128,约等于3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
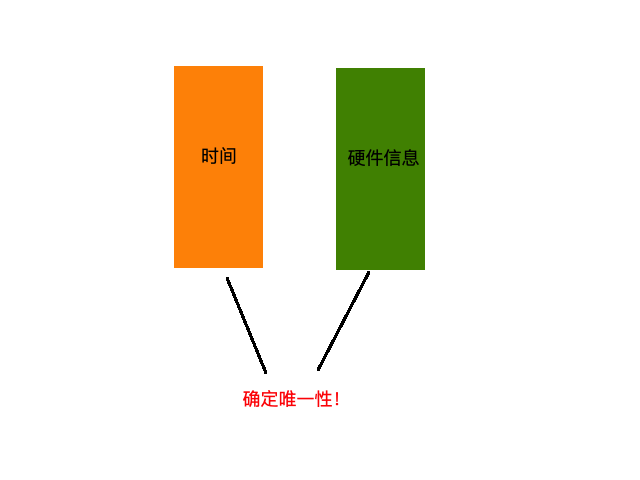
UUID是利用同一时空中的所有机器都是唯一的这一规则来确保唯一性的。
具体外形为:
通常由以下几部分组成:
- 系统时间
- 时钟序列
- 全局唯一的IEEE机器识别,如网卡MAC、机器SN等
生成方式多种多样,业界公认的是五种,分别是uuid1,uuid2,uuid3,uuid4,uuid5。
目前使用最广泛的UUID是微软的GUID。
优点
- 本地生成,性能极佳。无网络消耗
- 全局唯一
缺点
- 存储麻烦。16字节128位,通常以36长度的字符串表示,很多场景不适用
- 通常是字符串,非自增,无序,不利于做主键。每次插入都会对B+tree结构进行修改
- 破解相对困难,但是也不安全。参考”梅丽莎病毒事件,病毒作者制作的UUID包含Mac地址,被警方破解后,直接定位,抓捕归案😝”
snowflake
snowflake即雪花算法,Twitter发明的。
原理
外形长这样: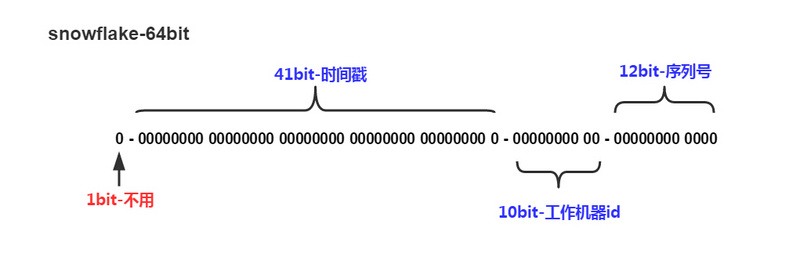
1位不用。二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0。41位,用来记录毫秒的时间戳。41位可以表示的数值范围是:0 至 2^{41}-1,减1是因为可表示的数值范围是从0开始算的,而不是1,转化为年则是2^{41}-1) / (1000 * 60 * 60 * 24 * 365) = 69年。10位,用来记录工作机器id。最多可以部署在2^{10} = 1024个节点,我们可以根据具体的业务来定制具体分配的机器数量和每台机器1毫秒产生的id序号number数。例如可以把10bit分5bit给IDC,分5bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以将内容配置在配置文件中,服务去获取。12位。用来表示单台机器每毫秒生成的id序号,12位bit可以表示的最大正整数为2^12 - 1 = 4096,若超过4096,则重新从0开始。即,每台机器1毫秒内最多产生4096个ID,足够用了。
最后将上述4段bit通过位运算拼接起来组成64位bit.
由于是64位bit,所以完全可以用数字来表示ID。
基本是根据:
优点
- ID为数字且时间位在高位,整个ID都是趋势递增的。
- 不依赖任何第三方库,完全可以自己写,且性能非常高。
- 可根据业务定制分配bit位,非常灵活。得益于
10位机器IDbit位。 - 不太容易破解
缺点
- 依赖机器的时间,如果机器时间不准或者回拨,可能导致重复
总结
在国内也得到了比较普遍的应用,各大厂根据其基本原理,生成了自己的规则:
- 百度的uid-generator:https://github.com/baidu/uid-generator
- 美团Leaf:https://github.com/zhuzhong/idleaf
更多精彩内容,请关注我的微信公众号 互联网技术窝 或者加微信共同探讨交流:

参考文献:
[flicker算法原文] http://code.flickr.com/blog/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/
[分布式唯一ID极简教程] https://mp.weixin.qq.com/s/cqIK5Bv1U0mT97C7EOxmnA
[分布式 ID 生成策略] https://mp.weixin.qq.com/s/UAvSUDFJ8Fr0a-Na2Vr22g
[分布式ID系列(2)——UUID适合做分布式ID吗] https://mp.weixin.qq.com/s/kZAnYz_Jj4aBrtsk8Q9w_A
https://segmentfault.com/a/1190000011282426
https://juejin.im/post/5d6fc8eff265da03ef7a324b#comment
https://segmentfault.com/a/1190000010978305
[Leaf——美团点评分布式ID生成系统] https://tech.meituan.com/2017/04/21/mt-leaf.html
[UUID的含义及实现原理]https://blog.csdn.net/reggergdsg/article/details/92091404
[通用唯一标识码UUID的介绍及使用] https://mp.weixin.qq.com/s/BjCL076USuhLj9GjhXDaTA
[UUID简史] https://www.infoq.cn/article/talk-about-the-history-of-uuid/?utm_source=tuicool&utm_medium=referral