啥叫I/O多路复用?
epoll又是个什么东西?
你或许看过很多文章,但是还是感觉云里雾里的,今天,我们抛开文字,释放动图,或许你就理解了。
I/O多路复用
通常的一次的请求结果如下图所示:
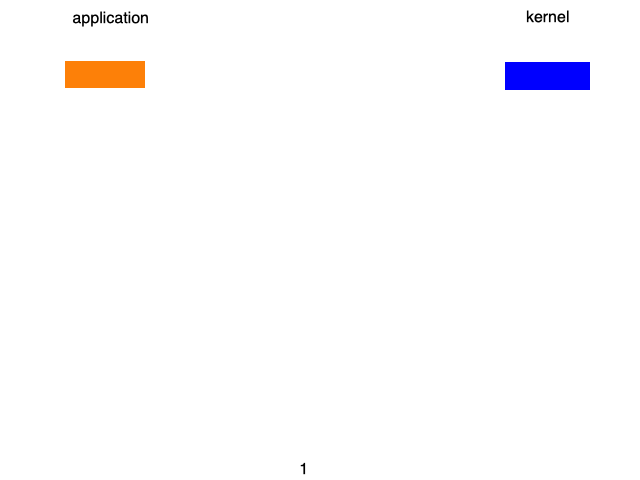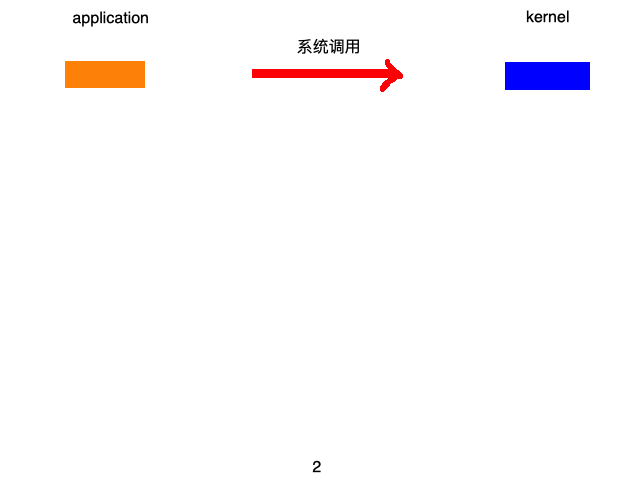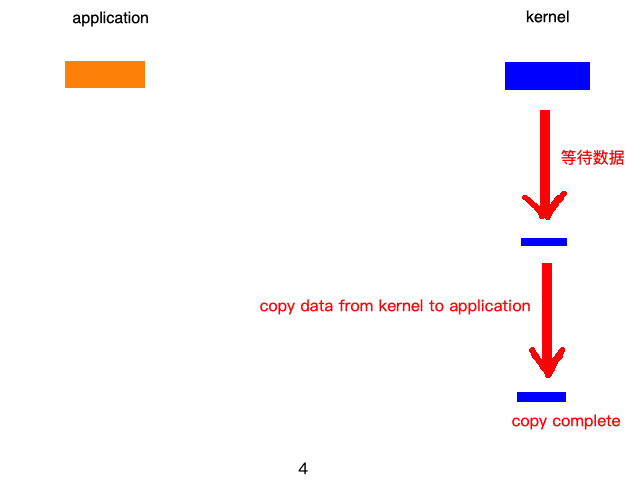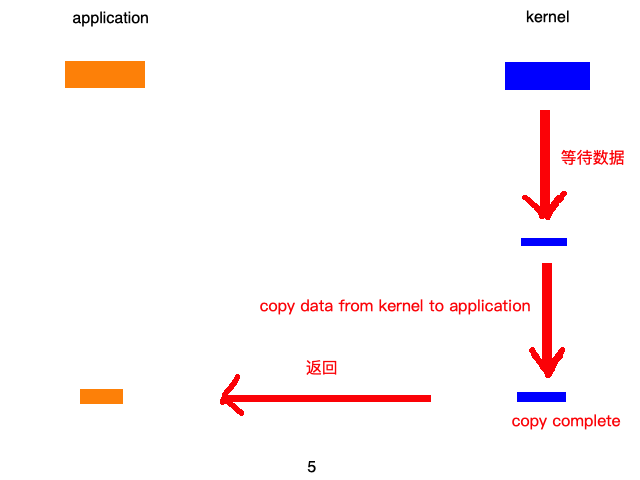
但是,服务器往往不会只处理一次请求,往往是多个请求,这一个请求,这时候每来一个请求,就会生成一个进程或线程。
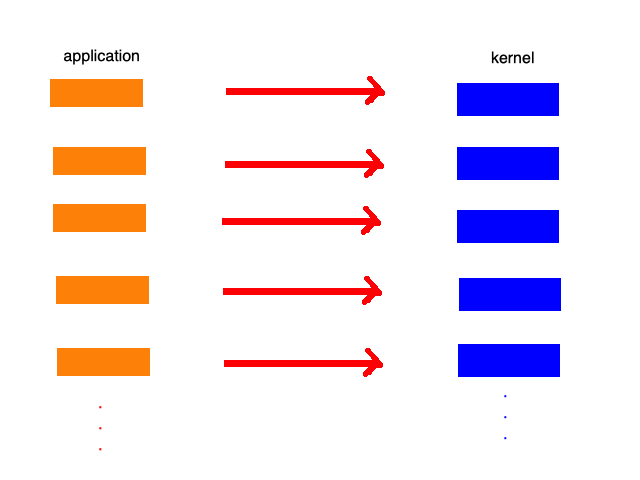
在这些请求线程或者进程中,大部分都处于等待阶段,只有少部分是接收数据。这样一来,非常耗费资源,而且这些线程或者进程的管理,也是个事儿。
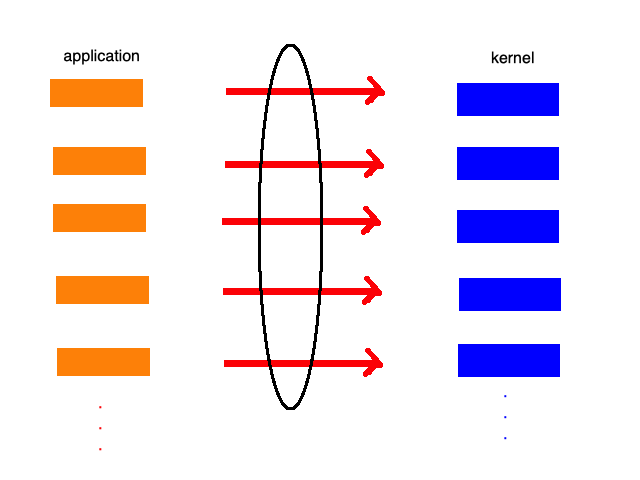
于是,有人想到一个办法:我们只用一个线程或者进程来和系统内核打交道,并想办法把每个应用的I/O流状态记录下来,一有响应变及时返回给相应的应用。
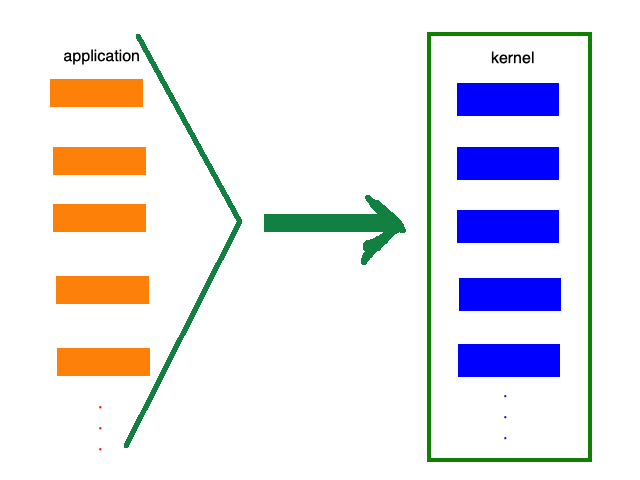
或者下图:
select、poll、epoll
select, poll, epoll 都是I/O多路复用的具体实现,他们出现是有先后顺序的。
select是第一个实现 (1983 左右在BSD里面实现的)。
select 被实现后,发现诸多问题,然后1997年实现了poll,对select进行了改进,select和poll是很类似的。
再后来,2002做出重大改进实现了epoll。
epoll和 select/poll 有着很大的不同:
例如:select/poll的处理流程如下:
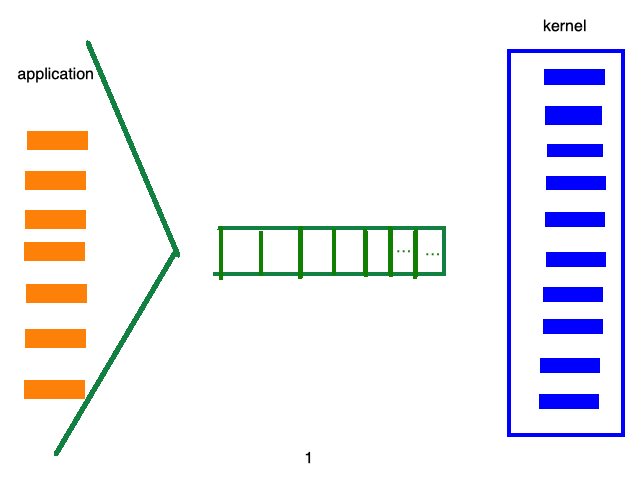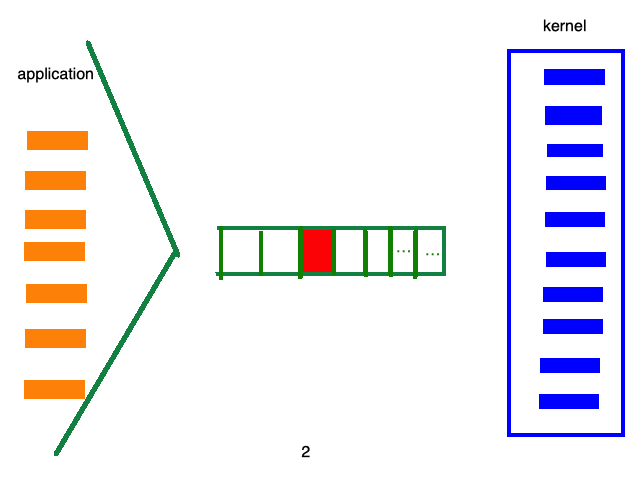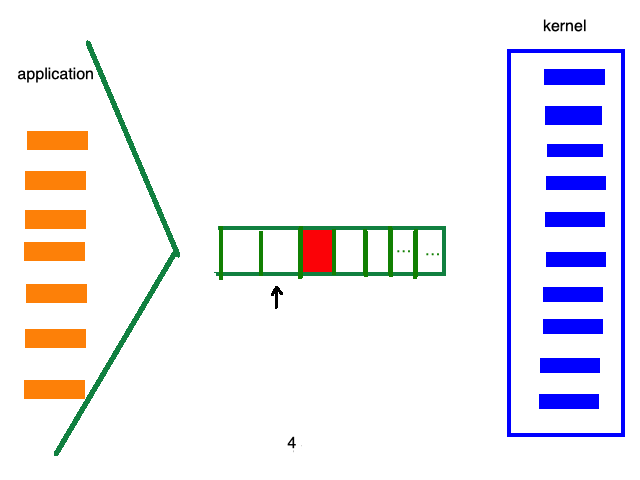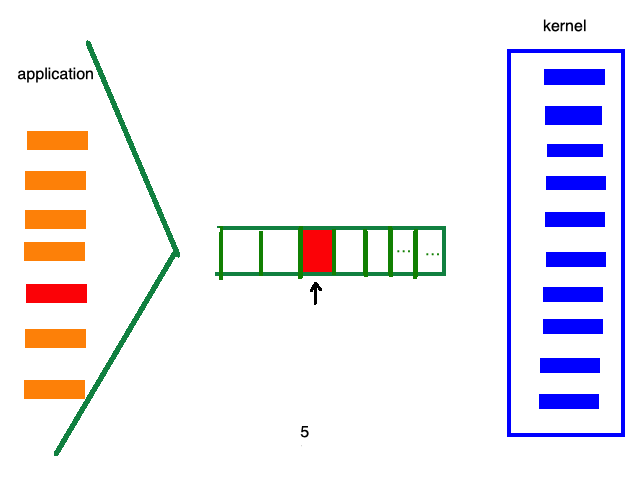
而epoll的处理流程如下:
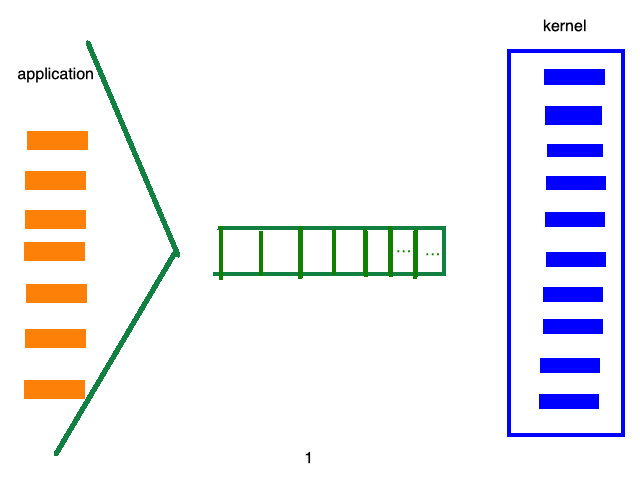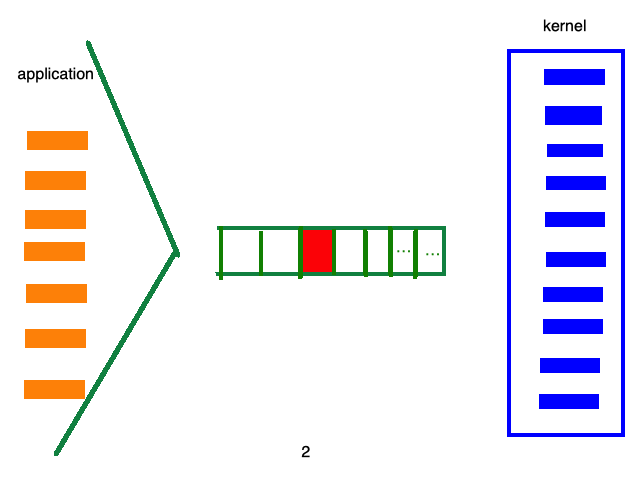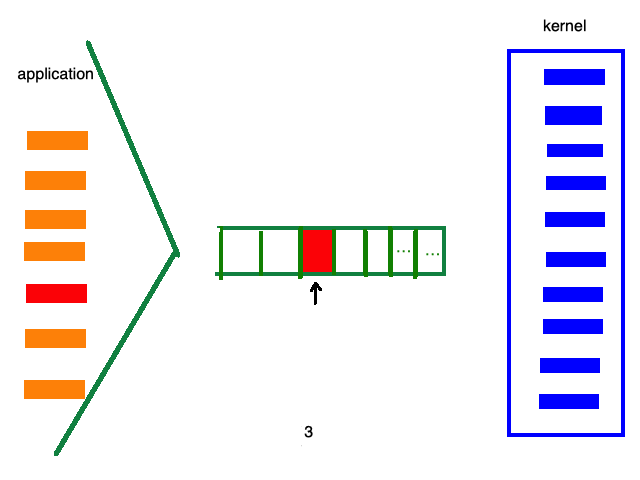
这样,就无需遍历成千上万个消息列表了,直接可以定位哪个socket有数据。
那么,这是如何实现的呢?
早期的时候 epoll的实现是一个哈希表,但是后来由于占用空间比较大,改为了红黑树和链表。
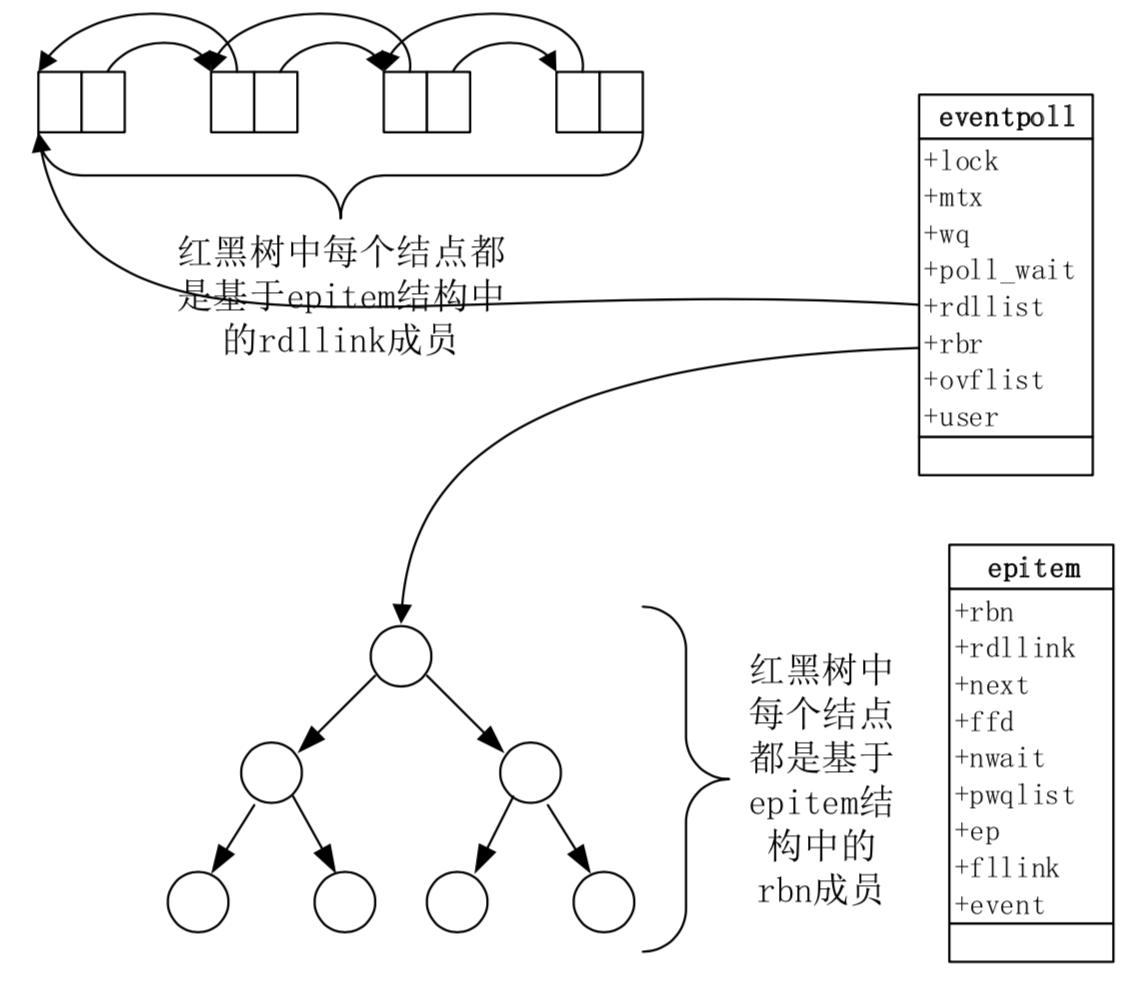
其中链表中全部为活跃的链接,红黑树中放的是所有事件。两部分各司其职。
这样一来,当收到内核的数据时,只需遍历链表中的数据就行了,而注册read事件或者write事件的时候,向红黑树中记录。
结果导致:
- 创建\修改\删除消息效率非常高:O(logN)。
- 获取活跃链接也非常快,因为在一个时间内,大部分是不活跃的链接,活跃的链接是少数,只需要遍历少数活跃的链接就好了
更多精彩内容,请关注我的微信公众号 互联网技术窝 或者加微信共同探讨交流:

参考文献: