我们程序中的变量大多被分配在内存的两个区域:statck和heap。
stack和heap
首先让我们一起来回顾一下进程的内存分配:
我们写的程序代码跑起来后,会是一个进程;OS会给我们的进程分配内存;内存结构大致如下:
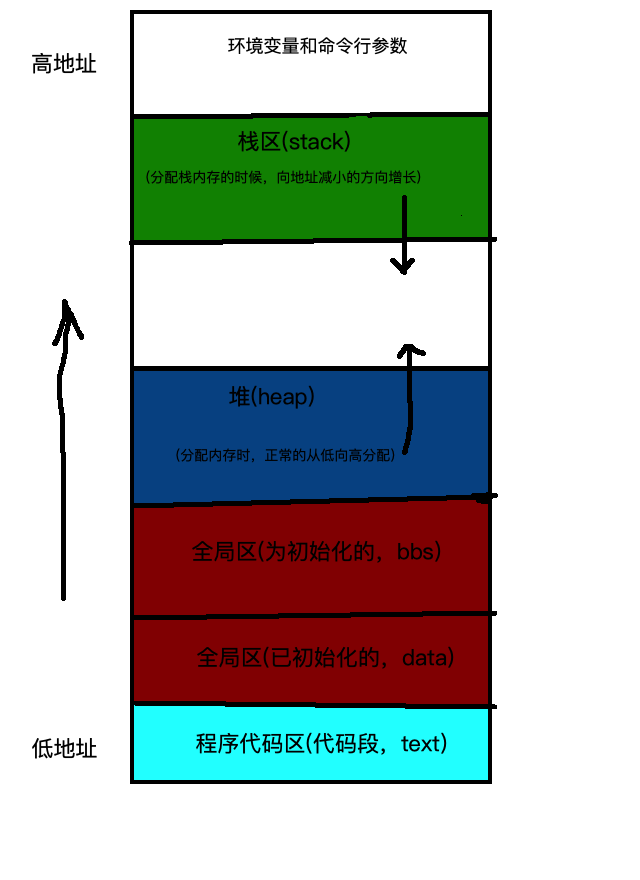
OS给一个进程分配的内存空间大致可以分为:代码区、全局数据区、栈(stack)、堆(heap)、环境变量区域以及中间空白的缓冲区六个部分。其中,数据的增长路径除栈(stack)是由高到低之外,其余的均是由低到高(可看图中数据箭头)。
我们思考一下,为什么栈(stack)区这么特殊和其他区域路径相反?还有,进程内存中stack和heap和数据结构中的stack和heap名字都相同,是有什么联系吗?请带着问题往下看:
进程内存中的stack和heap
stack : 是由程序侧通过系统调用向操作系统申请的,由操作系统管理和释放,不需要程序员手动管理;一般用于存放线程和函数中产生的临时变量。这块区域的数据使用速度较快,不用手动管理,省心省力。
heap:是由程序侧通过系统调用向操作系统申请的,但是需要程序员自行管理的内存区域,因为此区域的定位是global variable,用于存放全局的变量(虽然很多编程语言中不这么利用); 程序员需要手动或者通过GC及时free或者delete此内存区域中的数据,但是也要注意:如果频繁的进行删除和添加,会导致内存碎片。
数据结构stack和heap
我们再来看看数据结构中的stack和heap;
stack
后进先出LIFO的数据结构。
Heap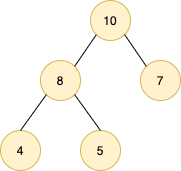
堆的定义:
- 完全二叉树
- 每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值
根节点是最大数的叫做“大顶堆”,根节点是最小数的叫做“小顶堆”。
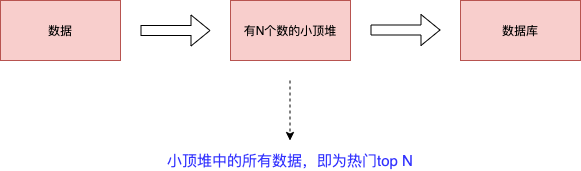
堆heap这种数据结构经常利用在“如何快速定位并获取到Top N最热门的xxx”,通常的做法如下图:
内存中的”stack和heap“与数据结构中的”stack和heap“的联系
一句话总结:进程内存中的栈区(stack)使用的数据结构就是stack,内存中的heap和数据结构中的heap则毫无关系。
看如下C代码:
1 | int main() { |
以上代码在栈区中的数据是这样的: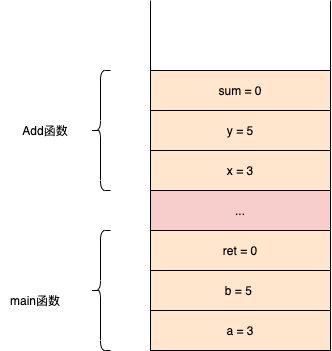
还及得上文中提到的:“进程内存中只有栈区(stack)数据是由高位向低位增长的,其余的均为由低位向高位增长吗?”
栈区用的数据结构是栈,函数变量的销毁和返回顺序用逆恰好符合stack先进后出的特点,我觉得这是栈区(stack)逆序增长很重要的一点。
但是,最根本的原因还是在于:历史遗留问题。请看下图:
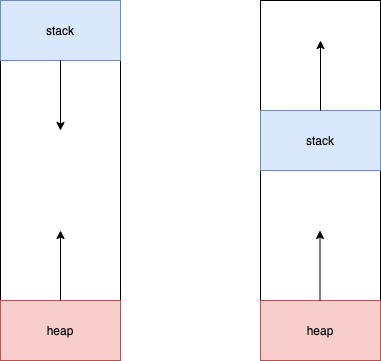
在当初那个内存空间及其短缺的年代,你认为左图还是右图更适合“缓冲区”?因为stack区域和heap区域大小都是动态分配的,都有“不确定性”,很显然,左图发生堆栈重叠更小,且更适合内存的充分利用。
Go变量的位置
我们在写C、PHP、Java的时候,可以很容易的知道,所写的变量所在的位置:带new、malloc等字段的,那一定是在堆上分配了,至于后续GC怎么处理,有没有引用继续关联,堆有没与释放,程序是否存在内存泄露…这都是后续处理的问题了;变量的存储位置是妥妥的堆上了。但是,在用Go的时候要注意,new、make等等关键字都不好使,Go变量的位置不是由写程序的程序员来决定的,而是Go自行处理;所以可能你的变量是new出来的,但是,最终也不一定分配到堆上,很可能是分配在栈上。
Go把变量的位置在哪儿这件事对程序员“隐藏”了,Go自行处理;因为Go认为:变量的存储位置,会对程序的性能有一定影响,而Go是计划打造对性能有极致要求的程序,因而自己管了。
Go是这么管的:
首先,栈stack上的效率肯定是比堆要高的,这算是常识;Go在编译期会对每一个函数变量做判断,如果不能够判断此函数中的变量在返回之后是否仍被引用到,就给把变量扔堆heap上,否则,就扔栈stack上。但是注意:如果变量非常大,还是会扔到堆heap上。
逃逸分析
我们是否有办法知道我们写的Go程序中变量的位置呢?
答案是有的,Go向开发者提供了变量逃逸分析的工具
1 | go build -gcflags '-m -l' main.go // 这里的main.go也可以是某个具体的二进制应用程序 |
下面对如下代码进行逃逸分析:
1 | import ( |
分析结果:
1 | ./main.go:11:16: main ... argument does not escape |
更多精彩内容,请关注我的微信公众号 互联网技术窝 或者加微信共同探讨交流:
