自1997年HTTP/1.1发布之后,HTTP/1.1便迅速占领了市场,时至今日(2022年)仍是当前使用最广泛的http协议。
但是,这并不能说明HTTP/1.1就完美无缺了,仍然存在很多问题。
HTTP1.1 当前存在的问题
当前HTTP1.1其实在协议本身的格式以及功能上在经历过HTTP0.9、HTTP1.0等几次迭代之后,已经逐渐趋于稳定。当前协议的主要问题是:协议制定初期原始依赖的底层协议带来的问题,即依赖TCP带来的问题:效率慢。
在http协议制定初期,谁也不会想到一个小小的浏览器能够出现这么丰富多彩的内容,最初的设定,仅仅是为了发布和共享文件,根本不会考虑”交互”的体验问题,压根想象不到当今的浏览器客户端一个页面下来,会产生这么多的请求。当初的设定很简单:只是为了让欧洲的学者之间能够共享文件,保证学术信息的分享;所以,可靠性是当初优先考虑的问题,TCP是可靠连接,理所当然就选择了TCP。
可是后来随着互联网的发展,当初选择TCP作为底层协议的弊端逐渐凸显:建立连接复杂,效率低。TCP建立连接需要三次握手和四次挥手,创建和断开过程繁琐,效率很低。
在http1.1协议之前,每一个请求都要新建一个链接;已知平均一个站点有65 ~ 79个请求(2019年统计),那么打开这么一个网站,就需要 65 ~ 79次请求…好在在http1.1之后新增了keep-alive字段,可以复用原有的TCP链接,无需每来一个请求就三次握手创建一个TCP链接,也无需一个响应结束四次挥手关闭一个TCP链接,在一定程度上提高了整体协议效率。但是,依然存在其他问题,例如:对头阻塞问题(Head-of-line blocking)。在http1.1协议下,同一个网站内所有HTTP请求的请求顺序是流水线式的顺序执行的,即虽然可能共用了同一个TCP链接通道,但是同一个TCP链接通道下的两个请求会存在阻塞等待的情况:如果前一个HTTP请求没有处理完,第二个http请求只能阻塞等待,这样停滞时间会影响整体协议的传输效率。并且,在不同的浏览器中,同一域名下并发连接的数目都是有限的,例如Chrome浏览器,同一域名下只允许最多6个并发连接数,这样一来,如果平均一个网站需要 65 ~ 79 个http请求(2019年官方统计数据),假设都在同一域名下,至少需要 65 / 6 11个请求等待,才能将所有请求发送完毕。而且假设其中一个链接通道中某个请求延迟或者等待,将直接阻塞后面队列中的请他请求的请求时间。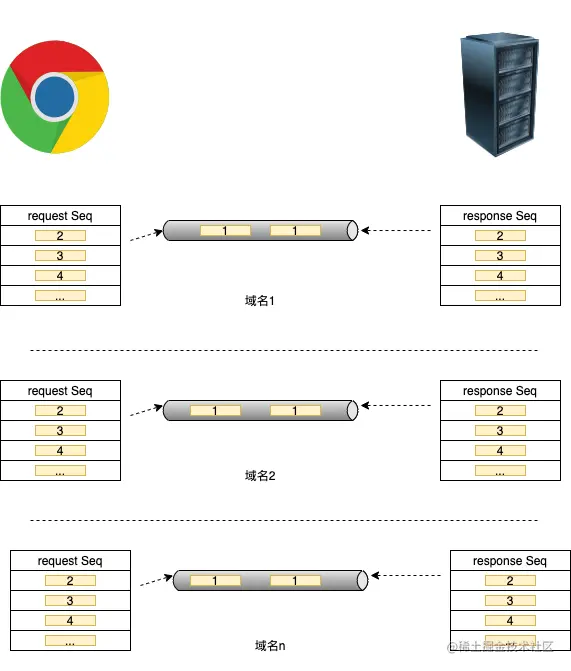
HTTP2.0 做的改进
为提高http的整体性能,http2.0在不改变当前协议整体格式及语义的前提下,对http协议的传输进行了优化,使得http2.0的整体传输效率得到了很大的提升。
可以点击以下链接感受一下速度:https://http2.akamai.com/demo
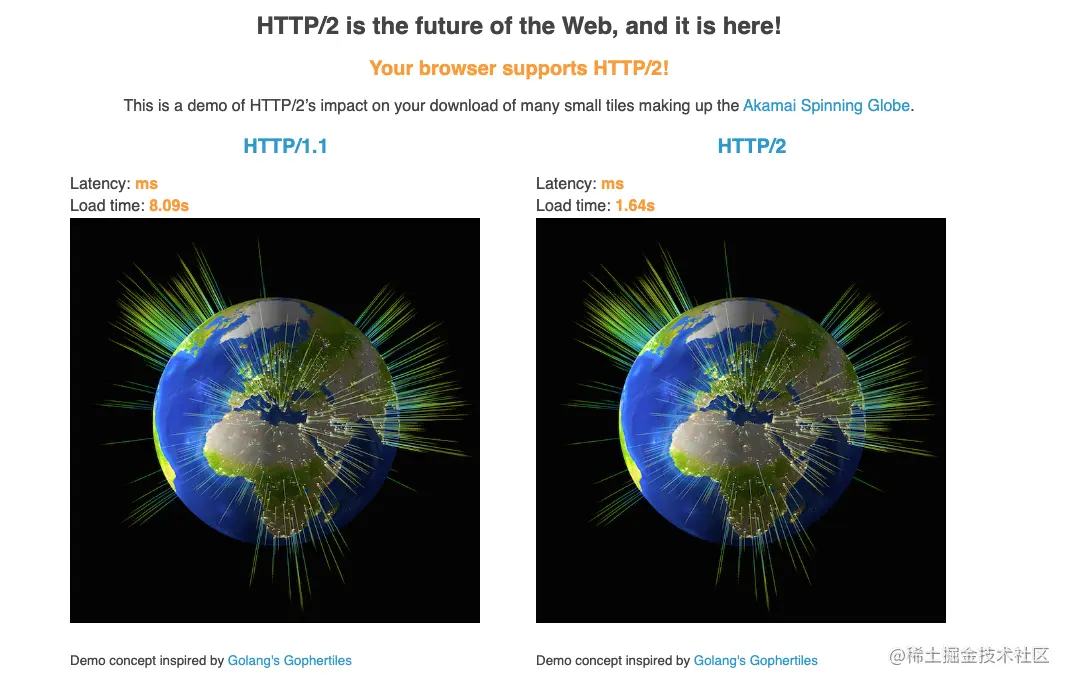
HTTP2.0的改进主要是针对HTTP性能的提升。
影响http网络通信性能的因素主要有两个:延迟 和 带宽。随着硬件能力的不断提升以及5G的普及,带宽逐渐不是影响网络通信效率的因素,延迟成了影响http网络通信的主要因素。而想要提升延迟,需要从网络协议的本身来找原因。早在2009年,Google就开始了对提升http性能的因素做研究;当时研发了一种叫做SPDY的协议,并在2012年得到了Chrome、Firefox以及Opera等浏览器的支持,并成功应用到了Google、Twitter、Facebook等大型网站中来;从此以后,越来越多的公司想要使用SPDY。
HTTP官方看到了这个趋势,决定仿照依赖SPDY协议的模型,对HTTP协议进行改造,于是就有了现在的HTTP2.0。前期HTTP2.0基本继承了SPDY协议,后来又在此基础上做了扩展。与SPDY协议类似,HTTP2.0遵循了如下原则:
- 目标是提升网络加载速度50%以上
- 禁止让当前HTTP用户做兼容修改,做到用户应用无感知切换
- 尽量的减少对当前网络协议结构的修改
HTTP2.0和SPDY的原理很简单,就是仿照TCP的拆包解包来解决当前HTTP的队头阻塞(Head-of-Line blocking)的问题,以实现多个请求并发传输、多路复用的效果。
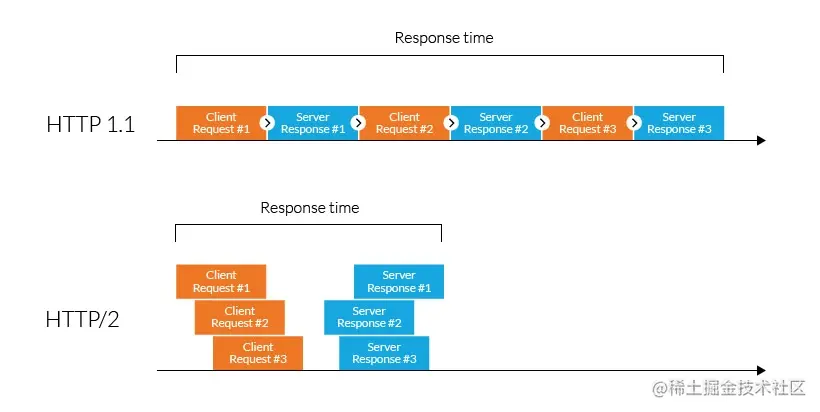
下面,就来详细说说http2.0的改进:
HTTP2.0 二进制分帧
二进制分帧,算是HTTP2.0最重大的改变了,HTTP2.0的多路复用就是基于这个才得以实现。
二进制分帧是在当前HTTPS的TLS协议之上,抽象了一层(也就是说,使用HTTP2.0的前提是必须使用HTTPS)。可以在传输的时候把一个请求拆分成多个很小的数据包,多个请求可以同时拆成许多数据包一起发送,到了服务端,服务端再根据数据包的序号进行拼接,得到完整的每一个请求。
这些拆分的请求最小粒度叫frame,按照类型可分为两类结构:Headers frame和data frame。headers frame是对请求头做了抽象,data frame是针对请求体做了抽象。
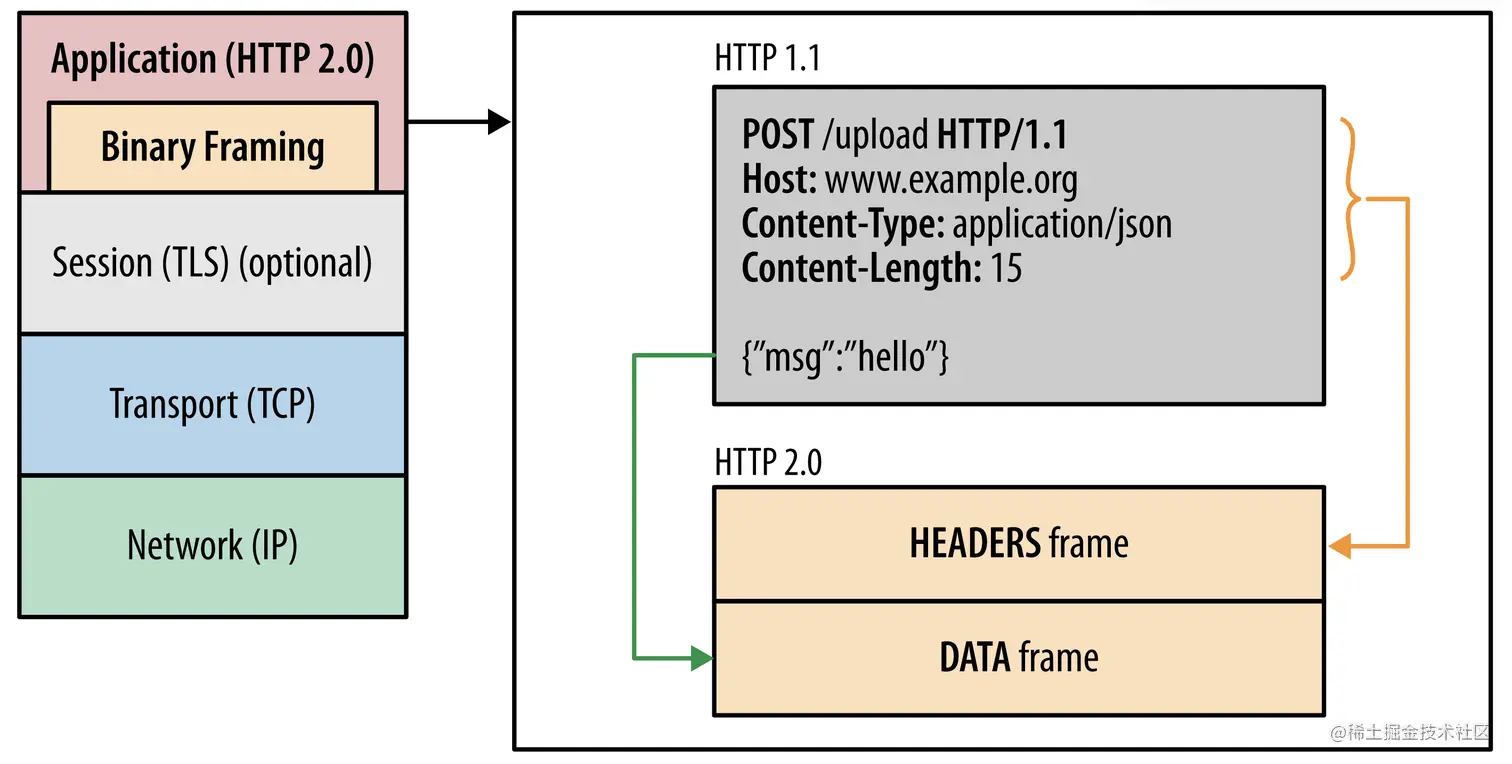
除了frame结构外,整个二进制分帧层还有message、stream两种数据结构,这几种数据结构存在包含关系:frame最小,message包含多个frame,stream包含多个message; frame、message、stream三种数据结构共同构成了http2.0的二进制分帧层。三种数据结构的联系和作用分别如下:
frame是最小的传输单位,内部有特殊标识,能够区分此frame属于哪个streammessage是逻辑层面的东西,在具体实现中没有体现,多用于表示是请求message还是相应message,一个messsage包含多个framestream是HTTP2.0传输的最大粒度的”包”,它包含唯一性字段和优先级信息,能够包含请求或者相应message。
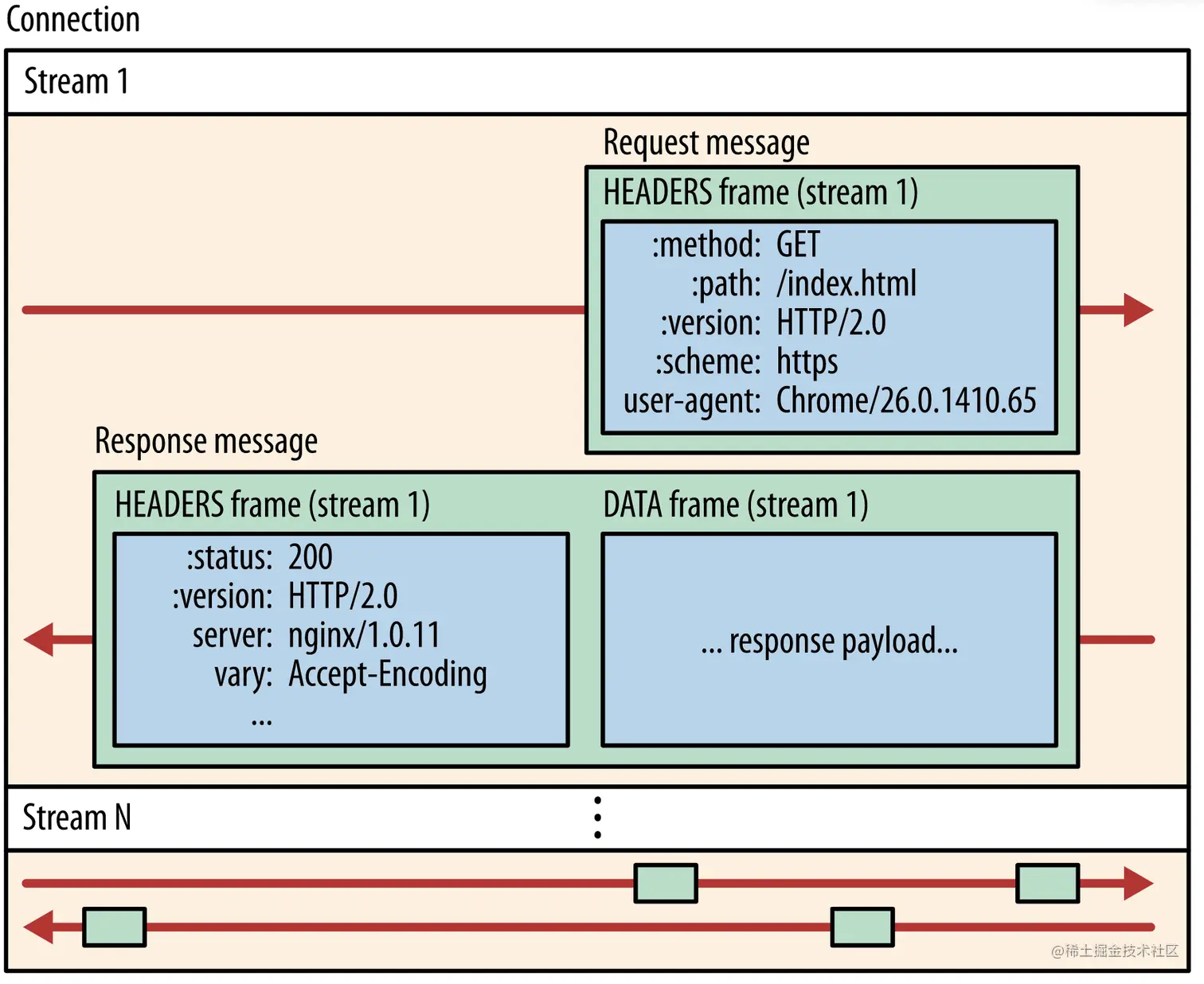
那么,http2.0具体是怎样实现多路复用、解决http1.1的队头阻塞(head of block)问题的呢?
首先,http2.0的所有请求都只在一条tcp连接中传输的,http2.0会把当前所有请求拆成无数小的frame(其实这时候已经区分出不同stream了)
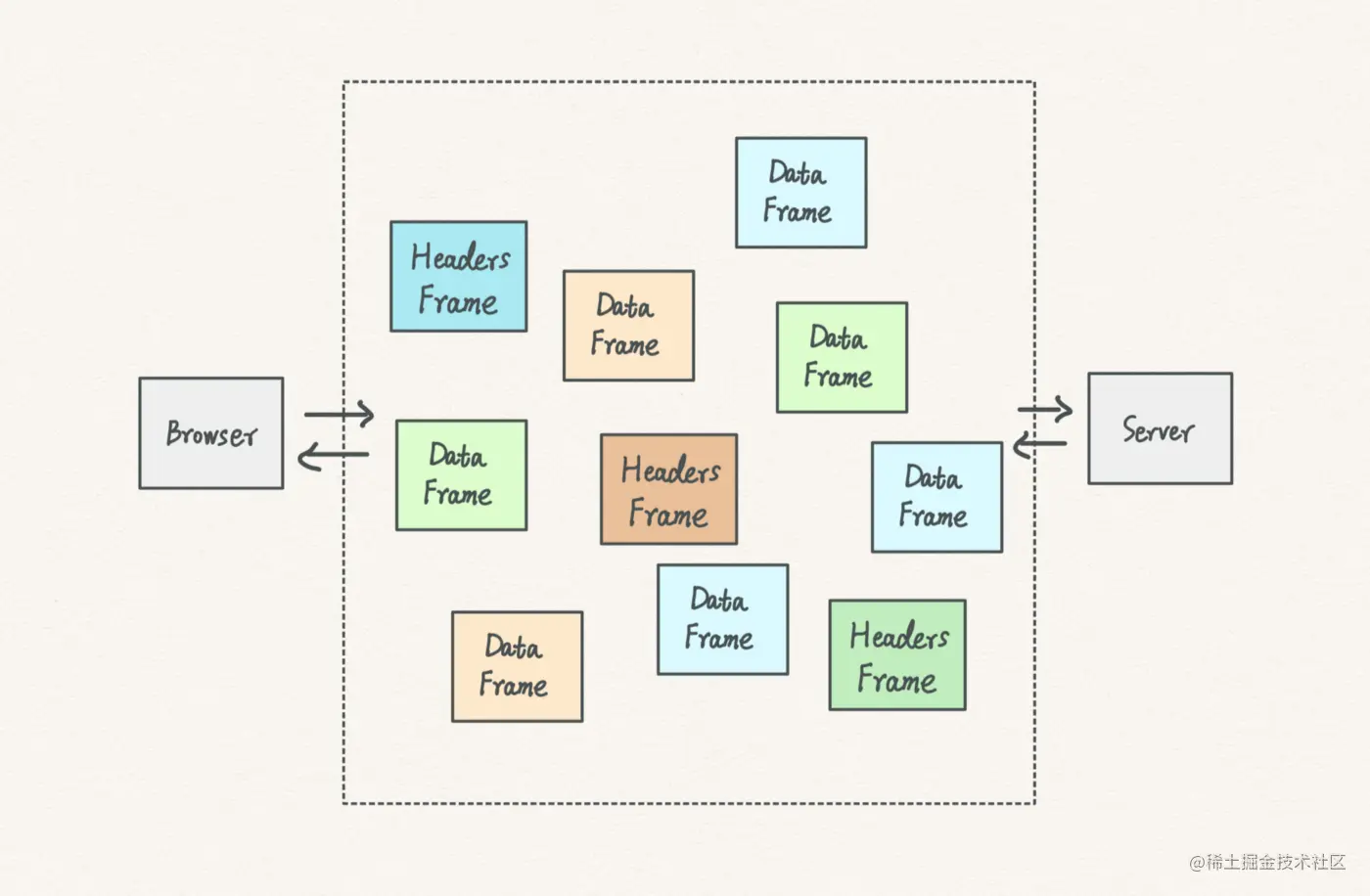
然后根据各个frame中的标识信息(frame中标有stream标识),组成一个个的stream,最后把各种的stream在一条tcp双向管道中进行传输。
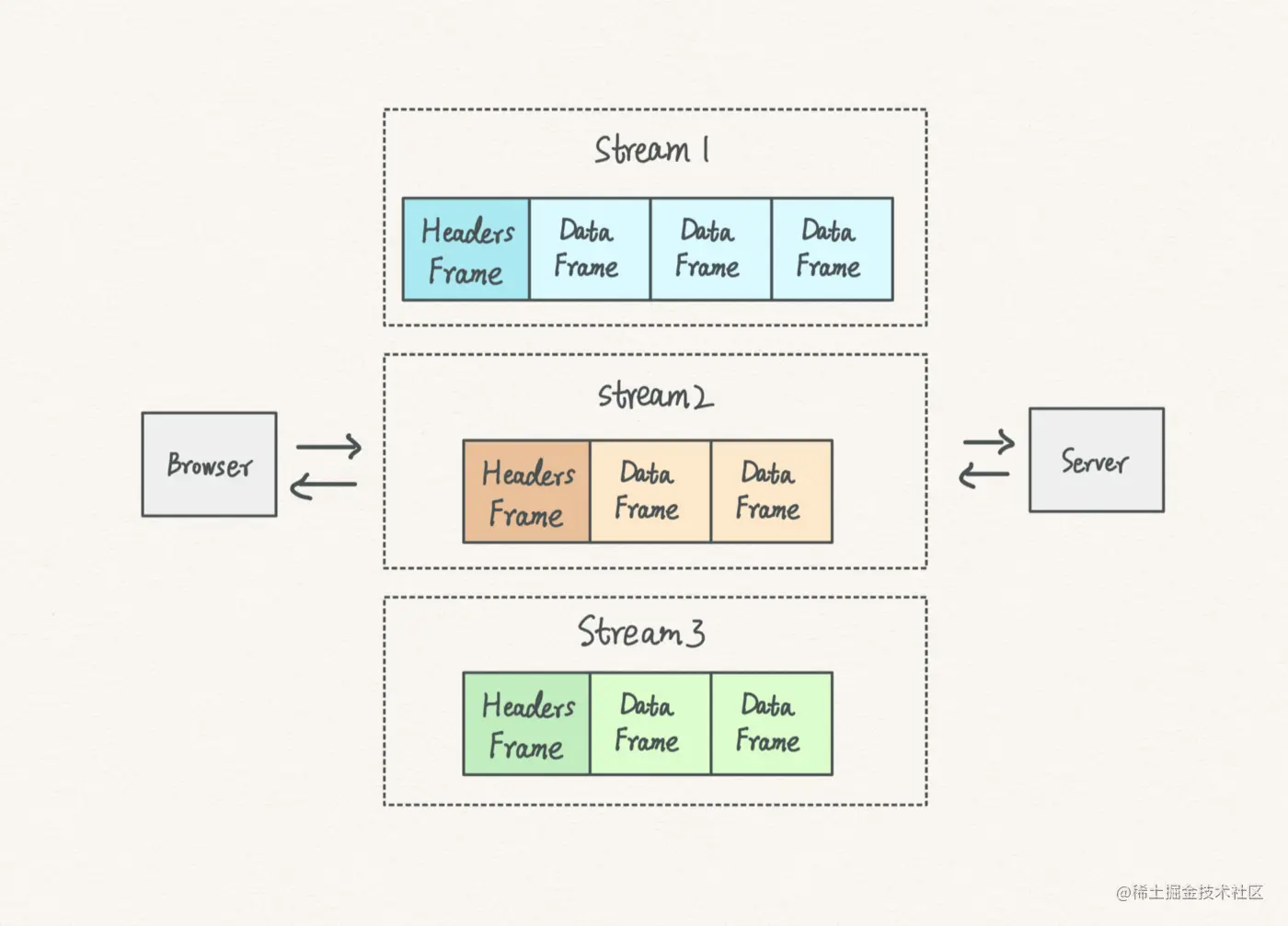
注意:虽然二进制分帧协议中有message结构,但是,这只是一种逻辑层面的结构,用于区分是请求还是响应信息片段,并不参与真正的协议实现。底层实现仅仅有stream和frame
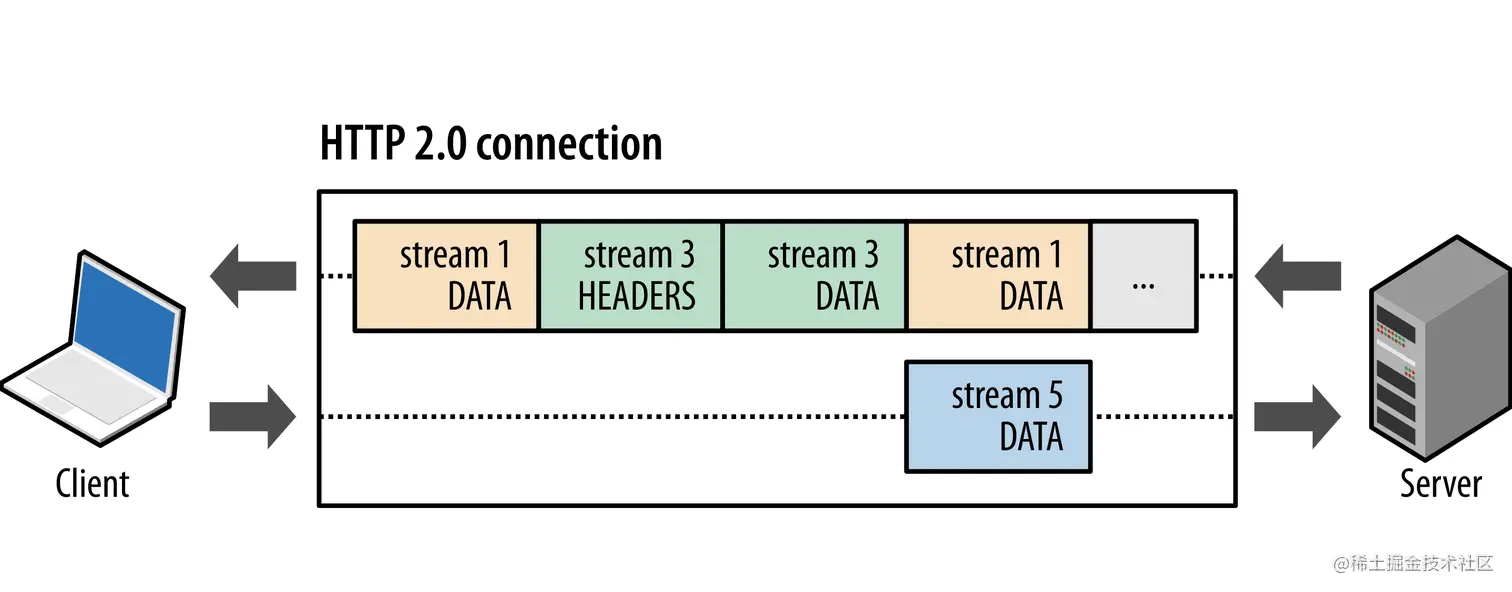
client端和server端在收到各类stream后,根据steam的标识,拼出完整的请求或者响应stream数组,再根据stream数组中的frame信息,解析出完整的请求或者响应信息。
这样,就实现了http在传输过程中的多路复用。
值得一提的是,在http2.0在传输过程中,我们不再使用纯文本,而是把请求的数据都采用二进制(0或者1)的形式进行传输,这样也减少文本转义带来的额外性能开销;
HTTP2.0 头部压缩
在http1.1传输过程中,请求体可以根据 gzip进行压缩,但是对请求头没有做处理,随着网站请求量的增多,在http2.0之后,对请求头也做了压缩处理。
对于一个站点,大部分的请求中请求头的信息都是重复的,不同的仅仅只有少数头部属性。
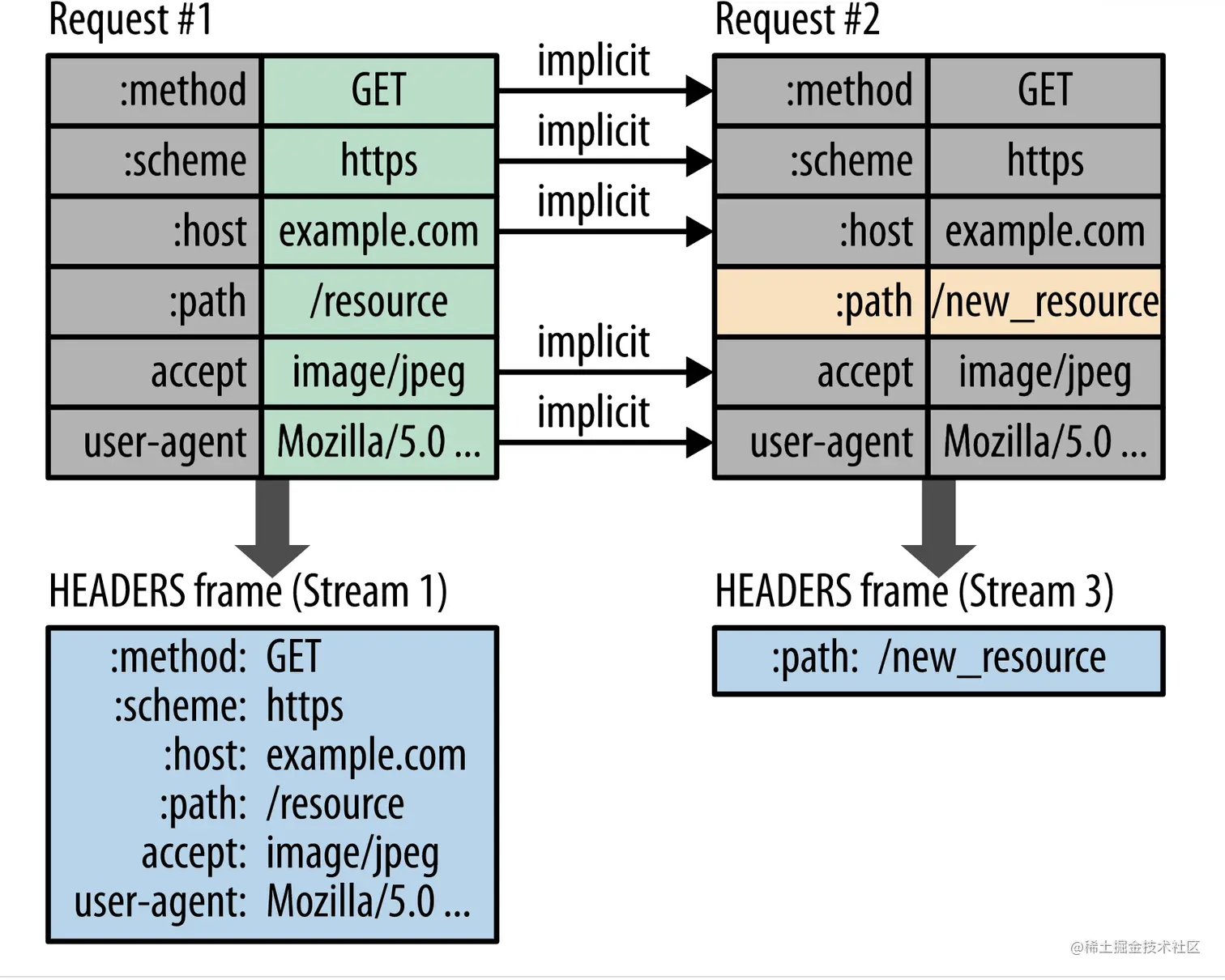
为了增加传输速率,http2.0在传输的时候,会维护一张请求头部信息的哈希表,并同时存储在客户端和服务端,每次传输的时候,如果发现传输的头部信息在哈希表中已经存在,则只传哈希表的index值,不再传输具体的内容,这样一来,就极大减少了数据的传输。同时,如果有新的头部字段,这张哈希表也会动态的在客户端以及服务端增加新值,后续再有相同字段的时候,将不会再传输,只会传哈希表的index值。
事实上,上文所谓的那张哈希表细分下来是两张表:一张叫静态表,一张叫动态表。静态表是存放HTTP协议本身固定的一些常见值:
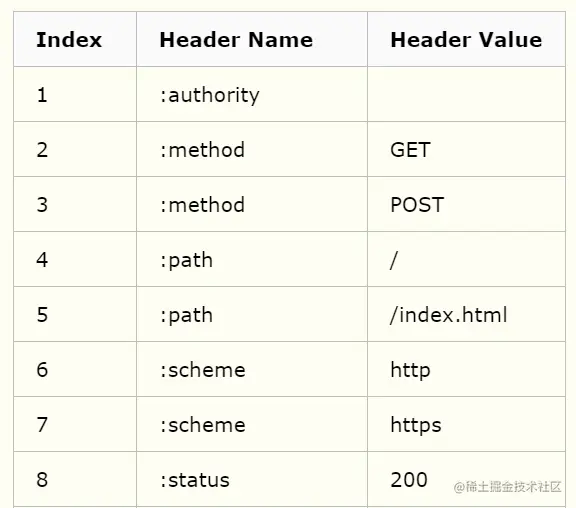
动态表存放一些网站特定的属性字段,而且会随着请求中字段的变化而进行增加。
之后,请求头的内容变成了除少量header字段外大部分是哈希表index值的数据;但是这还没有结束,http2.0还会将现有的数据内容进行霍夫曼编码处理,再一次进行压缩。
以上便是http2.0头部压缩的算法,叫做HACK算法。
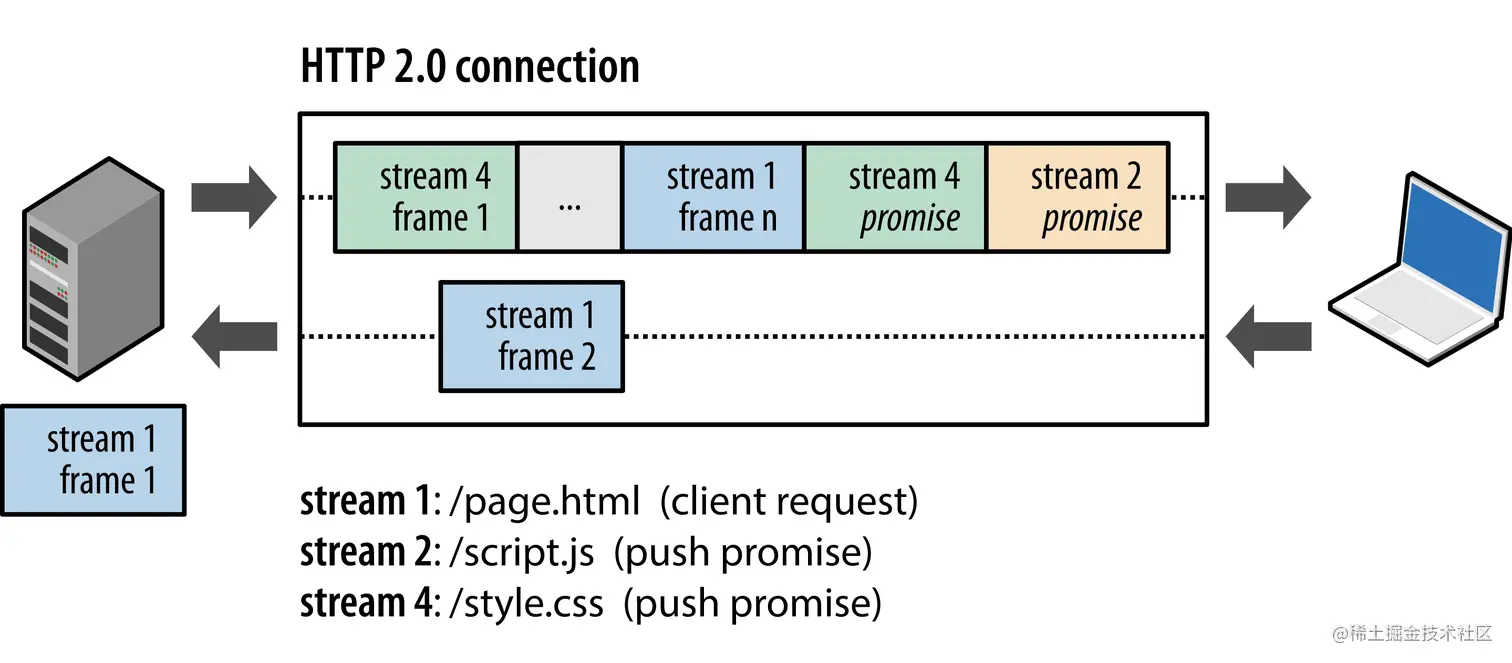
HTTP2.0 数据推送
不同于http1.1的请求-响应模式,http2.0可以由服务端向客户端推送消息,但这里的推送方式又有别于tcp、或者websocket的双向通信,有一定的局限性。
在常见的http1.1协议下,client端和服务端严格按照 “请求-响应”的方式进行通信。这样会出现一种情况:某些请求显得很多余。例如,请求一个网站页面,在返回主要的html文件后,html文件中内联的css
、js等文件内容必须通过额外的客户端请求,才能从服务端拿到数据;而这些内联的数据文件,是一定且必须拿到的,这样看来,http1.1场景下,这些内联的数据文件必须由客户端再次发起请求,才能得到服务端的响应数据;而在http2.0的场景下,服务端会根据文件中关联的其他文件,预判并主动推送下次请求中必须的数据。http2.0的数据推送仅限于此了,不同于tcp、websocket的双向通信,要特别注意。
这里可能会有人要问:“http提供了缓存能力,如果推送来的数据客户端缓存里有,该怎么办?”
其实很简单,如果服务端推送数据过来,客户端可以针对推送的数据自行选择放弃或者保存,但是如果客户端将推送来的数据主动放弃,这样其实就白白浪费了一次http响应传输;http2.0还有更好的方式是将客户端已有的缓存信息标识告诉服务端,服务端通过判断之后,只推送不存在的数据信息即可。